Unlocking the Power of RAG: How AI Can Query Your Own Documents
For the past couple of months, I’ve been exploring Retrieval-Augmented Generation (RAG), and it’s truly fascinating. The ability to query your own documents—whether it’s a developer guide, troubleshooting manual, or any textual content—is a game-changer for AI applications.
What is RAG?
RAG is an AI architecture that allows Large Language Models (LLMs) to access and use your own data for more relevant and accurate responses.
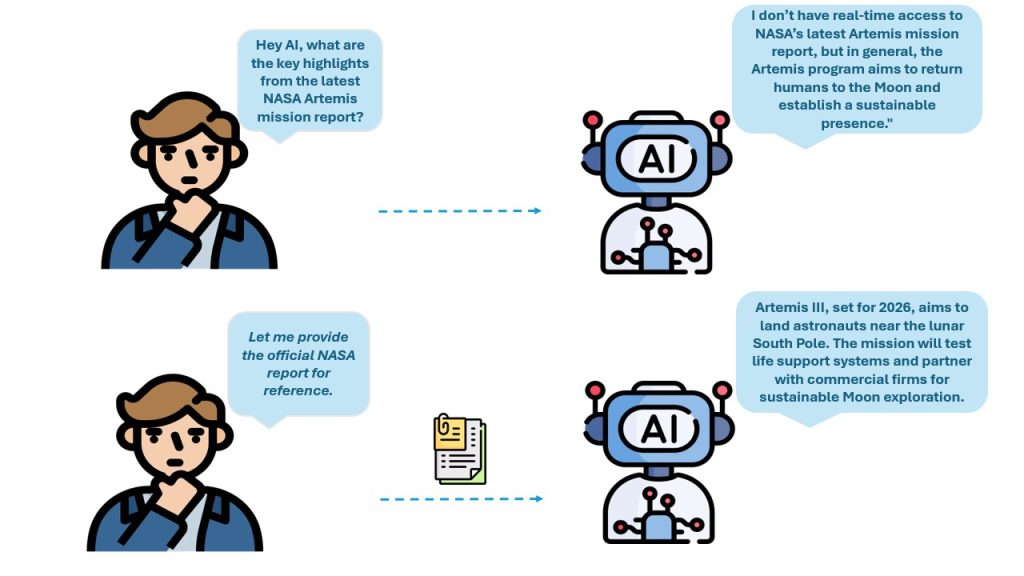
Think of an LLM as a brilliant researcher who has read thousands of books and articles. While this researcher is great at understanding and generating text, they may not have read your specific documents—such as internal policies, proprietary reports, or specialized knowledge bases.
Now, imagine if you could hand over the most relevant pages from your documents before asking a question. The researcher (LLM) would then use this new information to provide a context-aware and precise answer. That’s exactly how RAG works—it retrieves relevant data from a document store and integrates it with the reasoning power of an LLM to generate informed responses.
How Does RAG Work?
When you ask a question, RAG follows a structured process:
- Retrieval – The system searches and fetches the most relevant information from your document repository.
- Augmentation – The retrieved text is attached to your query to enhance context.
- Generation – The LLM processes both the query and the retrieved text to provide an accurate response.
Why is RAG Important?
Traditional LLMs rely only on their training data, which may be outdated or lack your private/company-specific knowledge. With RAG, you get custom, up-to-date answers based on your own documents—making AI more practical, reliable, and business-ready.
What’s Next?
In upcoming posts, I’ll break down the core components of RAG, share insights on real-world implementations, and discuss the challenges I faced while building RAG-powered systems. Stay tuned!